incomplete first draft…
1 Like
My recommendations:
-
Use 21 bytes for the destination bitcoin address instead of 25 bytes. We don’t need to encode the checksum. See https://en.bitcoin.it/w/images/en/9/9b/PubKeyToAddr.png
-
Increase the (optional) memo to a variable length field of 30 bytes. With 25 bytes, I can include a bitcoin address. With 20 bytes, I can include a ripemd-160 hash of anything. This makes the memo field much more useful.
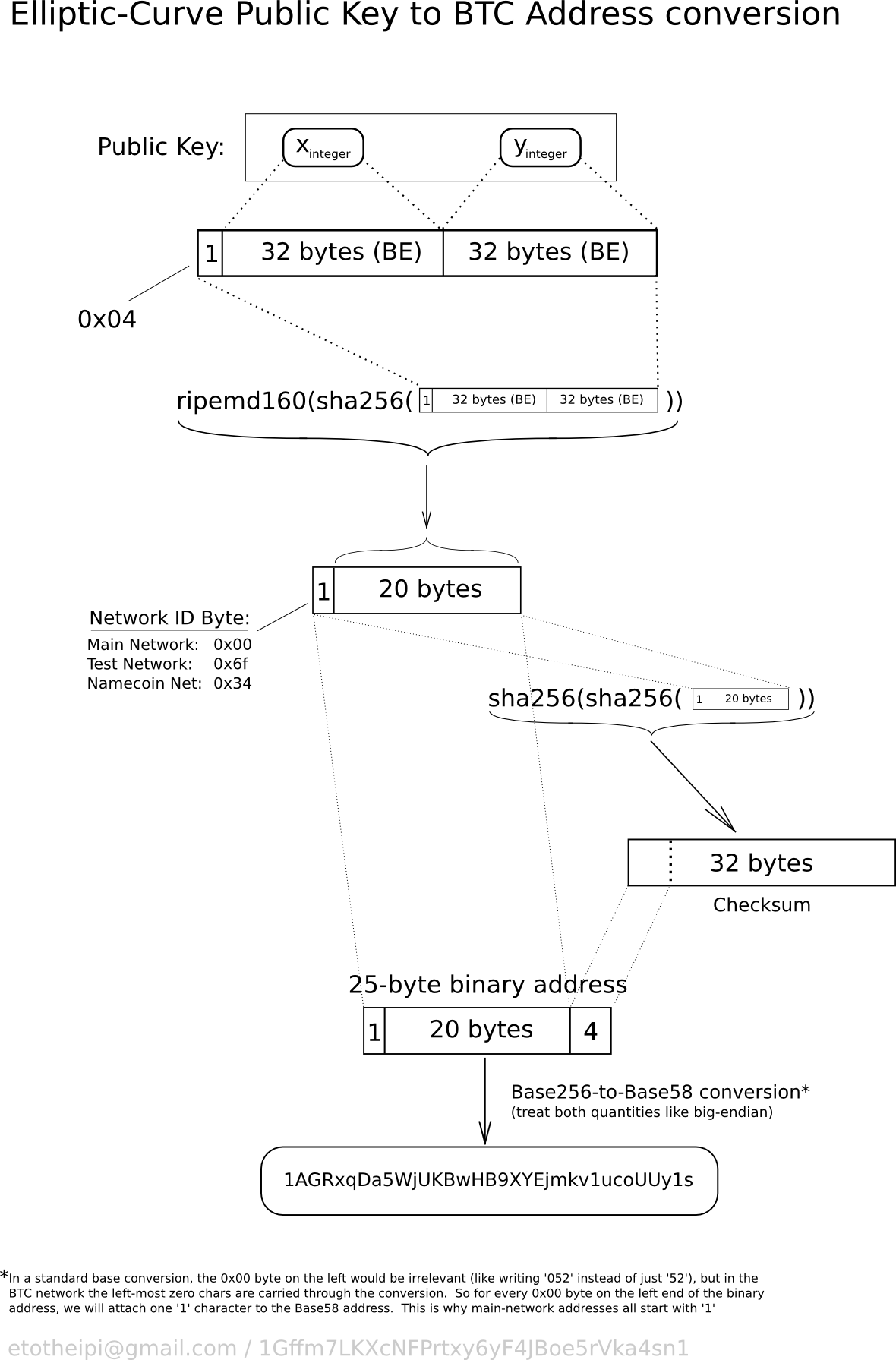{kind=link}
This still keeps the transaction size small enough to fit into an OP_RETURN.
Got it, my concern was that you needed the add’l bytes to differentiate between a p2pkh and p2sh address. From the graphic, it looks like the preceding byte is all thats necessary so 21 bytes should work.
Regarding the memo field, the thought process behind keeping it at 8 bytes was to allow for additional expansion of the enhanced send message type in the future. I can certainly understand the usefulness of expanding it.
To use Monero as an example, they use 32 bytes…
I wish we could use 32 bytes so we could include a sha256 hash. But we are 1 byte short.
80 bye OP_RETURN
-8 bytes: CNTRPRTY prefix
-4 bytes: for a transaction type (4 bytes is overkill, but I don’t want to change this now)
-8 bytes: asset type
-8 bytes: quantity
-21 bytes: destination address
That leaves 31 bytes. If we use 1 byte for a length prefix (not strictly required), then that leaves us 30 bytes to still fit into an OP_RETURN.
I like the idea of adding a change address and/or multiple sends quite a bit. But encoding multiple quantity amounts in the small space we have is problematic.
We could fit another quantity value by reducing the Payment ID. The message could be parsed with the assumption that the change output address is where the change quantity amount is credited.
Thinking more about a change address, this would be a pretty major change in how wallets interact with the Counterparty ecosystem. Best to leave that for another CIP.
It is a good example, however, of why we should probably leave some extra room in the message data by not filling the rest of the space with a Payment ID.
We could fit another quantity value by reducing the Payment ID. The message could be parsed with the assumption that the change output address is where the change quantity amount is credited.
Agreed. We can pare down the payment ID significantly if needed. For the exchange usecase, 32 bits (4 bytes) would be probably enough to encode every user (and they could just use a second address if they somehow cap out).
If we need to allow for an extra byte, the payment ID could be implemented as 7 bytes (or 4) instead of 8, and it would still be able to represent unique users well above the current user count. Though 7 feels a bit ugly, and I would prefer round multiples of 2, 4 bytes feels a bit too crowded.
For me a 25 or 30 byte memo field option is more important than saving room for the future. If we want to implement change addresses or multi-sends in the future that need the room, we can create a new transaction type for that. We have plenty of transaction type ids available.
So, for example:
- type 2 is enhanced send with a long memo (30 bytes) - implementing now
- type 3 is enhanced send with a change address - implement in the future
Exchange addresses are only one use case for the memo field. Other examples are payment invoice IDs, return bitcoin addresses for token vending machines, proof of existence hashes, proof of ownership signatures.
1 Like
Does the 8 byte CNTRPRTY prefix need to be this long?
Will it be possible to shorten it to e.g. CNTRP for this and future send types, or will this mess up the code / cause issues?
EDIT: The protocol specification states that:
For identification purposes, every Counterparty transaction’s ‘data’ field is prefixed by the string CNTRPRTY, encoded in UTF‐8. This string is long enough that transactions with outputs containing pseudo‐random data cannot be mistaken for valid Counterparty transactions.
Does not this imply that the risk of a random string being mistaken for Counterparty transaction is 1 / (2^8)^8 = 1 / 2^64 = 1 / 1.8e19 ? Practically speaking, it is so unlikely it never happens.
However, if it does happen, then what? It burns a tiny bit of CPU cycles before it’s declared an invalid Counterparty tx, right? So basically it adds a microscopic, negligible cost.
If the prefix is reduced to 5 chars, the chance of a random string being mistaken is 1 / (2^8)^5 = 1 / 2^40. Thus still insignificant.
I understand there are other considerations, like how add adding a new prefix will complicate the existing code. That’s beyond me, so I’ll leave it to others to have an opinion on this
so judging by your comments I take it you guys feel the send should remainj withi opreturn bounds?
I think a 30 byte Payment ID (memo) field is fine. My biggest sticking point is that it fits within the 80-byte OP_RETURN.
Yes. The issue for me is just pragmatism.
Multisig encoded transactions are not relayed in Bitcoin 0.12.x (which is what most CP implementations are using right now). And pubkeyhash encoding is inneficient and expensive.
OP_RETURN is the one practical encoding option right now.
Your analysis is right on here.
We could also save 2 bytes in the transaction ID. It is 4 bytes long now and could be shortened to 2 bytes.
Making either of these changes would be a burden both now and in the future. Is it worth it for 3 or 5 bytes? I’m not sure.
I’ve updated the gist to include a 30-byte payment ID field. Changing the transaction ID length isn’t really in the scope of this CIP but I think down the road it makes sense to free up a couple of bytes in the message.
Are there any objections to the Enhanced Send CIP in its current form? If not, @deweller can you assign this a number?
1 Like
I’m assigning this as CIP 9. I made a couple of minor notes on the gist. Please submit a PR when you are ready.
1 Like
@loon3 - Regarding this
Payment ID, 30 bytes (Hex) preceded by a 1 byte Payment ID length value. The Payment ID to be stored as a hex string to allow versatility for end users and developers.
We don’t need the 1 byte length value here. Since it is the last item in the message, we can can save the 1 byte and infer the length automatically. This is the way the description field works in issuances.
Do you want to remove this and save a byte?
So as not to duplicate discussion, I think it makes sense to keep this in the pull request… https://github.com/CounterpartyXCP/cips/pull/16